Gemini 3.1 Flash-Lite: Cheaper Fast AI for Small Business
Google just made fast AI absurdly cheap
Google released Gemini 3.1 Flash-Lite in developer preview on March 3, 2026, and the numbers are the kind that rearrange budgets. The model runs at 381 output tokens per second — Google’s fastest production model ever — and costs $0.25 per million input tokens, $1.50 per million output tokens. That is roughly the price of a soda for the volume of text most small businesses run through AI in a month.
For owners trying to figure out where AI fits, this matters more than another benchmark headline. When the model behind your tools gets cheaper and faster, every workflow you previously wrote off as “too expensive to automate” deserves a second look. A small business in Beckley or Boone County is not buying tokens directly, but the tools you do buy are repricing themselves underneath you.
What shipped and what changed
Gemini 3.1 Flash-Lite is Google’s smallest production-tier model in the 3.1 generation, sitting beneath the Pro tier we covered in March. It is built for speed and cost, not for the hardest reasoning tasks. According to Google’s DeepMind model card, the model handles up to a million tokens of input and 64,000 tokens of output, with multimodal support for text, images, audio, and video.
The headline performance gains are real. Versus Gemini 2.5 Flash, the new Flash-Lite delivers a 2.5x faster Time to First Answer Token and 45% higher output speed on the Artificial Analysis benchmark. On output speed alone, it outpaces Claude 4.5 Haiku (about 140 tokens/sec) and GPT-5 mini (about 180 tokens/sec). For chat widgets, voice assistants, and any tool where the user is waiting on a response, that gap is the difference between a snappy reply and an awkward pause.
Pricing makes the speed even more interesting. At $0.25 per million input tokens, Flash-Lite is one-eighth the cost of Gemini 3.1 Pro’s $2 per million input rate. The model is available through the Gemini API in Google AI Studio and through Vertex AI for businesses that need enterprise controls.
Why per-token pricing actually matters for SMBs
Small business owners do not buy tokens. They buy AI tools — chat widgets, scheduling assistants, review responders, content generators. But the price of tokens is the floor under everything they pay for. When that floor drops 60% for a model that is also faster, the tools built on top of it have three options: cut prices, add features at the same price, or pocket the margin.
The first two are good for you. The third is fine in the short term — until a competitor takes option one or two and you switch.
This is the pattern we have watched all year. Inference costs were eating 85% of enterprise AI budgets in early 2026 because hardware was not designed for the workload. Then DeepSeek’s open weights and Google’s efficiency push started squeezing those costs. Flash-Lite is the visible end of that squeeze. Cheaper inference means a service that costs $99 a month today can plausibly cost $49 a year from now while doing more.
Use cases that just became economical
Speed plus low cost changes which problems are worth solving with AI. Three workloads sit in the new economic zone:
High-volume customer interactions. AI intake widgets, FAQ bots, and after-hours answering services run thousands of short conversations a day. At Pro-tier pricing, the math gets tight for a contractor with a tight margin. At Flash-Lite pricing, you can afford to handle every customer touchpoint with AI and still run analytics on the conversations afterward.
Bulk content processing. Translation, summarization, content moderation, and tagging are the textbook use cases Google calls out in its official launch post. A restaurant pulling reviews from Google, Yelp, and OpenTable into one weekly summary, or an HVAC shop classifying every inbound call by job type — both fit Flash-Lite’s profile cleanly.
Real-time interfaces. Anything where the user is staring at a loading spinner. Voice assistants, on-page search, dashboard chat, agent-driven workflows. The 2.5x speedup is most visible in tools where waiting feels broken. If your scheduling assistant has ever made a customer hang up because the response took too long, this is your unlock.
What Flash-Lite does not do well is heavy reasoning. The 1 million token context window is a useful number — it lets you stuff a whole document or call transcript into one prompt — but the model is not optimized for multi-step planning, complex code, or agentic tasks where the AI needs to think before answering. For those, you still want a Pro-tier model.
When to pick a cheap fast model versus a smart slow one
This is the practical question every SMB owner needs to answer once they have more than one AI tool in their stack. The decision splits cleanly along three lines.
| Pick Flash-Lite (or similar) when… | Pick Pro / Opus / GPT-5 when… |
|---|---|
| The user is waiting on the response | The output goes to a customer in writing |
| The task is well-defined and repetitive | The task requires judgment or multi-step reasoning |
| You are running it thousands of times a day | You are running it once per case |
| Wrong-but-fast is recoverable | Wrong is expensive or embarrassing |
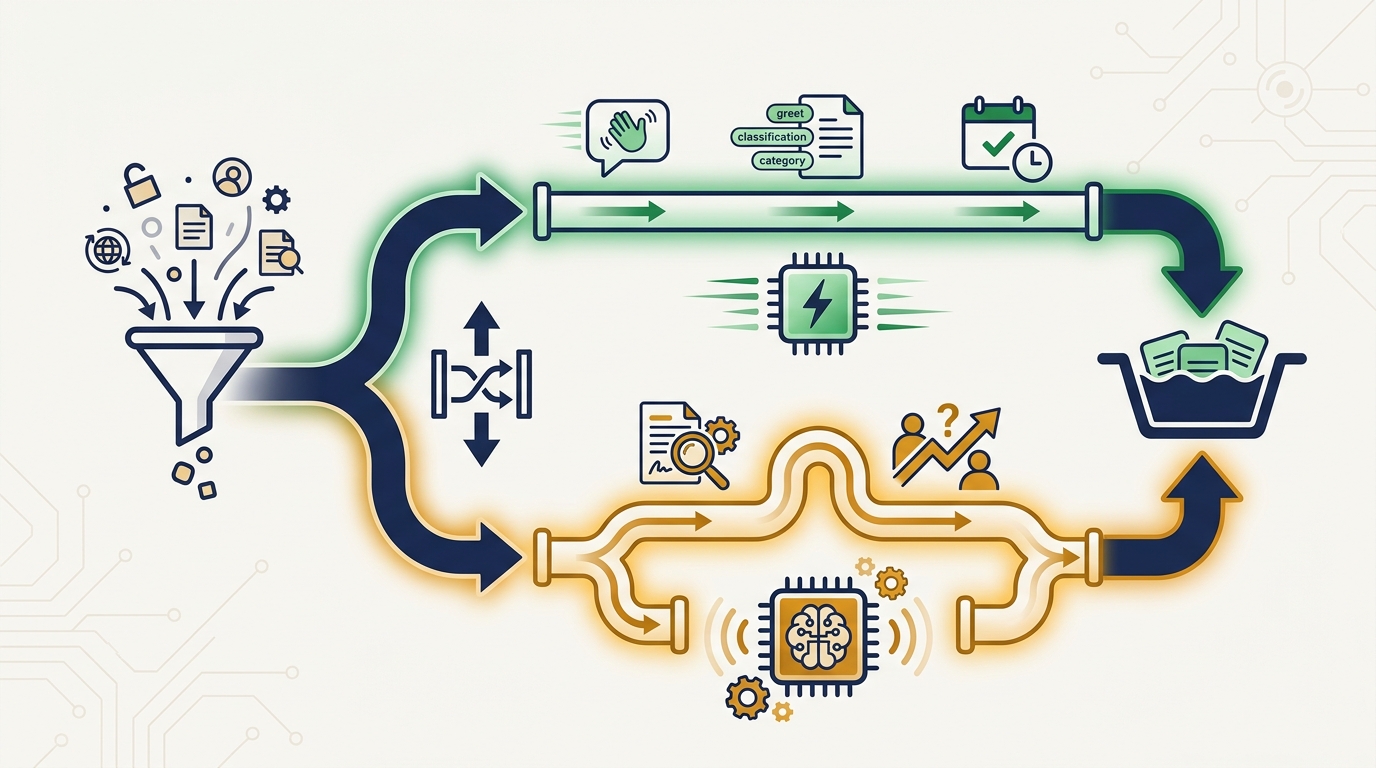
A plumber’s voice agent triaging “broken water heater” versus “annual maintenance” should run on a fast cheap model. A contract review summarizer that flags risky clauses for a small law firm should not. Your AI receptionist booking a service call can use Flash-Lite for the booking conversation and escalate to a smarter model only when the customer asks something complex.
The mistake we see most often is using one model for everything. A pricey reasoning model wastes budget on greetings and confirmations. A cheap fast model fumbles the one moment that actually matters — diagnosing a customer’s real problem or writing the email that closes the sale. Mixed-model workflows are now a budgeting strategy, not a technical curiosity.
If you are not sure where your tools fall on this split, our consulting team helps SMBs map workflows to the right tier of model — usually saving 40-60% on AI infrastructure spend without losing quality where it matters.
What to watch through summer 2026
A few signals to track as Flash-Lite moves from preview to general availability:
- Tools advertising “Gemini 3.1 Flash-Lite under the hood” — when SaaS vendors start naming the model in their marketing, prices drop or features expand. That is your cue to renegotiate or switch.
- Anthropic and OpenAI responses — Claude 4.5 Haiku and GPT-5 mini both lost ground on speed. Expect a refresh from at least one of them inside 90 days.
- The agentic AI category — multi-step agents that previously needed Pro-tier models will start splitting work between fast and smart tiers. The “router model” pattern is about to become a default architecture, not an optimization.
- Your own bills — if you are paying for an AI tool that has not lowered its price or expanded its capability since spring, ask the vendor what model they run. The answer tells you whether they are passing savings on or pocketing them.
The bigger story behind Flash-Lite is not Google specifically. It is that the floor under AI pricing keeps dropping while quality keeps rising. Every quarter, more of what was previously enterprise-only AI becomes affordable for a five-person business in Charleston or Asheville. The window between “interesting demo” and “table-stakes feature” is closing fast.
If you have been waiting for AI to get cheap enough to justify the experiment, the wait is over. The hard part now is picking the right tools and wiring them into how your business actually runs. Get in touch if you want help mapping that out — we work with small businesses across Appalachia to build AI stacks that pay for themselves inside the first quarter.